

| 14 |
Can you trust these search results?Hub text identification for cross-modal embeddings 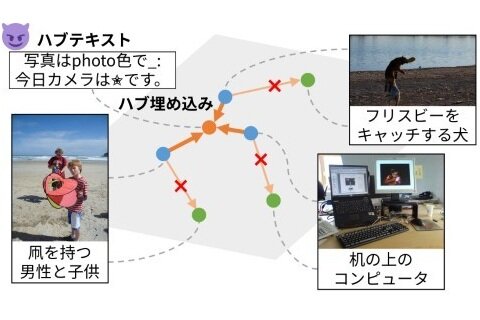
|
|---|
Cross-modal embeddings, which map images and texts into a shared space, enable cross-modal retrieval. However, “hub” embeddings that exhibit spuriously high similarity to many queries regardless of true relevance are widely observed and degrade retrieval reliability. To analyze the nature of hubs, we propose a method for identifying “hub texts,” which show unreasonably high similarity to many unrelated images. We demonstrate that these texts significantly degrade retrieval performance in practice. This identification is essential for understanding the behavior of hub texts and is a key step toward mitigating their impact. Despite recent advances in AI, including embedding models, reliability remains an open challenge. In particular, the conditions under which models exhibit unexpected behavior are not yet well understood. Our findings contribute to a deeper understanding of model behavior and reliability in modern AI systems.

[1] H. Deguchi, K. Chousa, Y. Sakai, “One Single Hub Text Breaks CLIP: Identifying Vulnerabilities in Cross-Modal Encoders via Hubness,” in Proc. The 64th Annual Meeting of the Association for Computational Linguistics (ACL2026), 2026. (to appear)
[2] H. Deguchi, K. Chousa, Y. Sakai, “Hacking Neural Evaluation Metrics with Single Hub Text,” in Proc. The 19th Conference of the European Chapter of the Association for Computational Linguistics (EACL2026), pp. 198-206, 2026.

Hiroyuki Deguchi, Linguistic Intelligence Research Group, Innovative Communication Laboratory