

| 06 |
Finding features in data fast and accuratelyAcceleration of feature selection with group regularization 
|
|---|
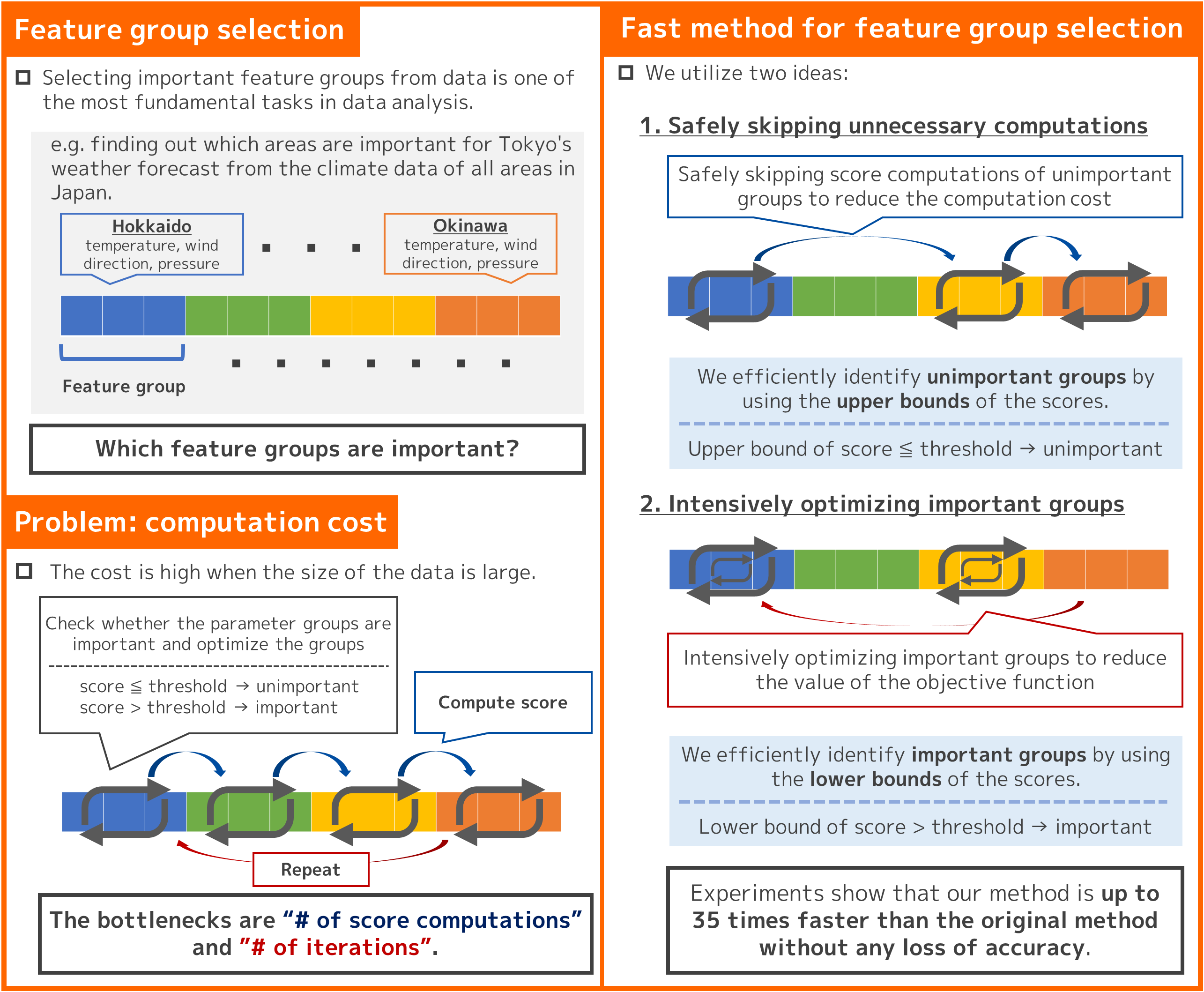
Selecting important feature groups from data is one of the most fundamental tasks in data analysis. However, the computation cost is high when the size of the data is large. In this study, we propose a fast method for feature group selection without degrading the accuracy. It safely skips unnecessary computations and intensively optimizes important groups. As a result, our method is up to 35 times faster than the original method without any loss of accuracy. In addition, our method has no additional hyperparameters and no additional tuning costs. It will be possible to create value from complex and large scale data by speeding up the analysis of data with complex structures such as groups. We create value from a wide variety of data and contribute to society.
[1] Y. Ida, Y. Fujiwara, H. Kashima, “Fast Sparse Group Lasso,” in Proc. Neural Information Processing Systems (NeurIPS), 1700-1708, 2019.

Yasutoshi Ida / Software Innovation Centor
Email: cs-openhouse-ml@hco.ntt.co.jp