

| 07 |
Privacy-aware machine learningDistributed learning algorithm and medical application 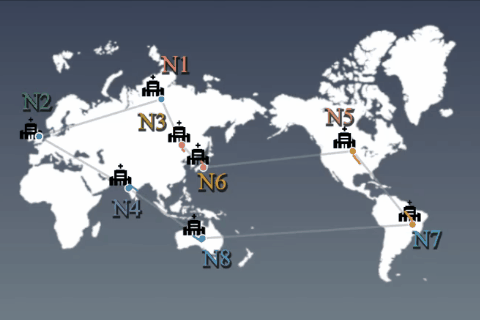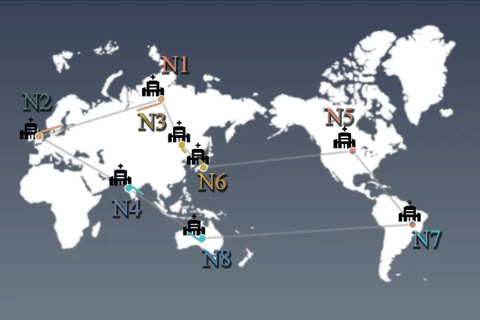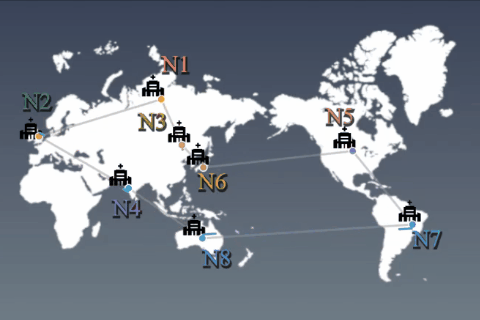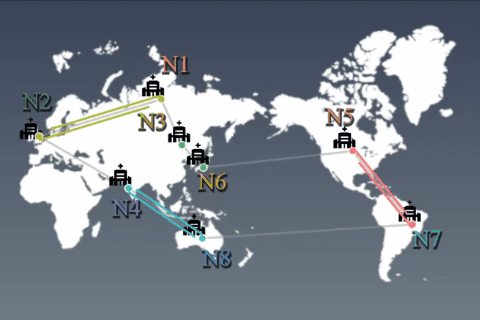
|
|---|
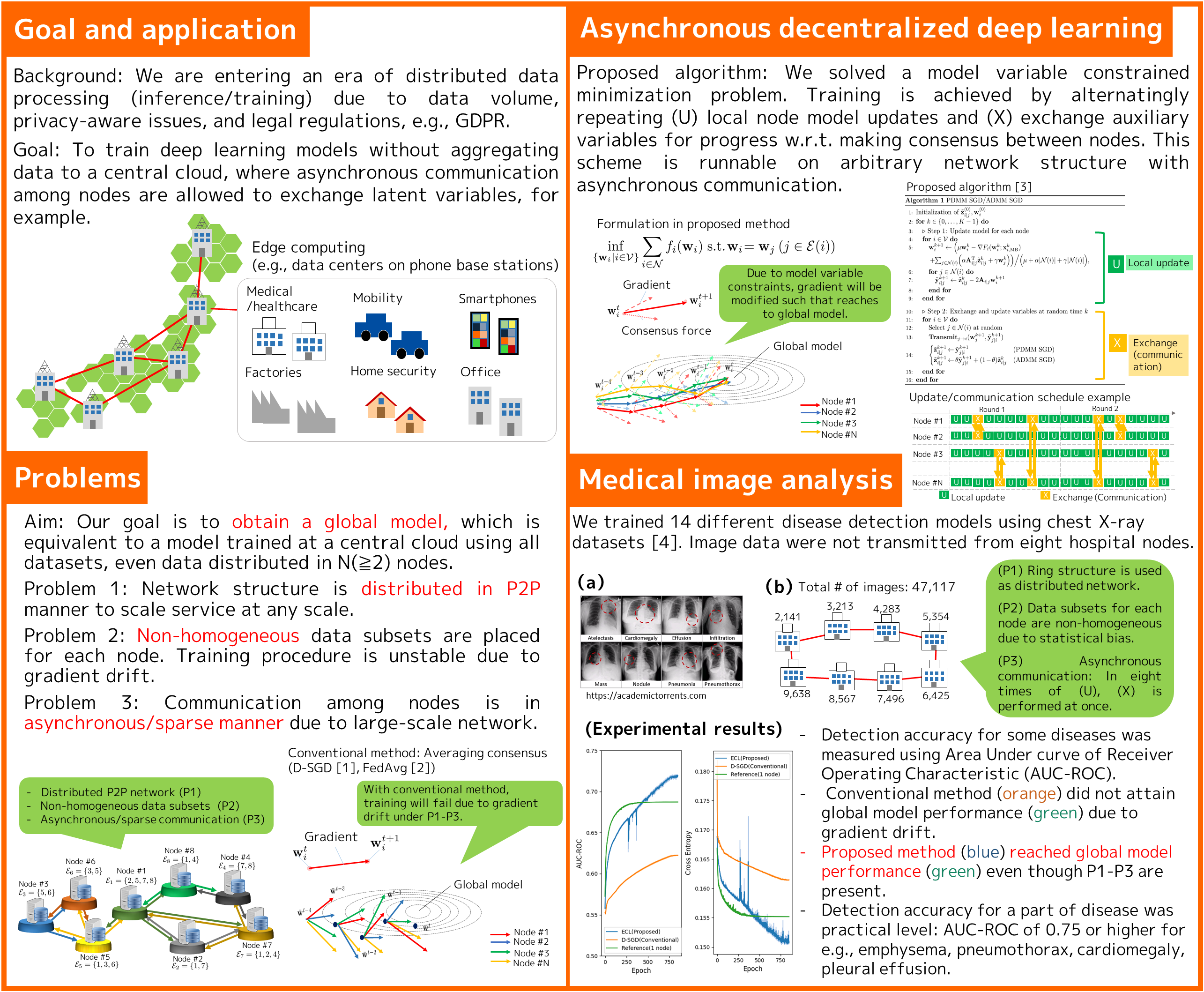
While use of massive data benefits on training deep learning models, aggregating all data into one physical location (e.g. a central cloud) may not be possible due to data privacy concerns. For example, according to the EU GDPR, data transmission should be minimized among processing nodes. Our goal is to construct training algorithms to obtain global deep learning models that can be adapted to all data, even when individual nodes only have access to different subsets of the data. We assume that this algorithm is allowed to communicate between nodes in an asynchronous/sparse manner, exchanging such information as model variables or their update differences. However, data are prohibited from being moved from the node on which they reside. We aim to indirectly exploit the overall data across countries and provide high performance services for such industries as the medical/health-care field while protecting privacy.
[1] J. Chen, A. H. Sayed, “Diffusion adaptation strategies for distributed optimization and learning over networks,” IEEE Transactions on Signal Processing, Vol. 60, No. 8, pp. 4289–4305, 2012.
[2] B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. y Arcas, “Communication–efficient learning of deep networks from decentralized data,” in Proc. Artificial Intelligence and Statistics (AISTATS 2017), pp. 1273–1282, 2017.
[3] K. Niwa, N. Harada, G. Zhang, W. B. W Kleijn, “Edge-consensus learning: deep learning on P2P networks with nonhomogeneous data,” in Proc. the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD 2020), pp. 668–678, 2020.
[4] National Institutes of Health (NIH) clinical center, ChestXray14 data set.

Kenta Niwa / Learning and Intelligent Systems Research Group, Innovative Communication Laboratory
Email: cs-openhouse-ml@hco.ntt.co.jp