

| 16 |
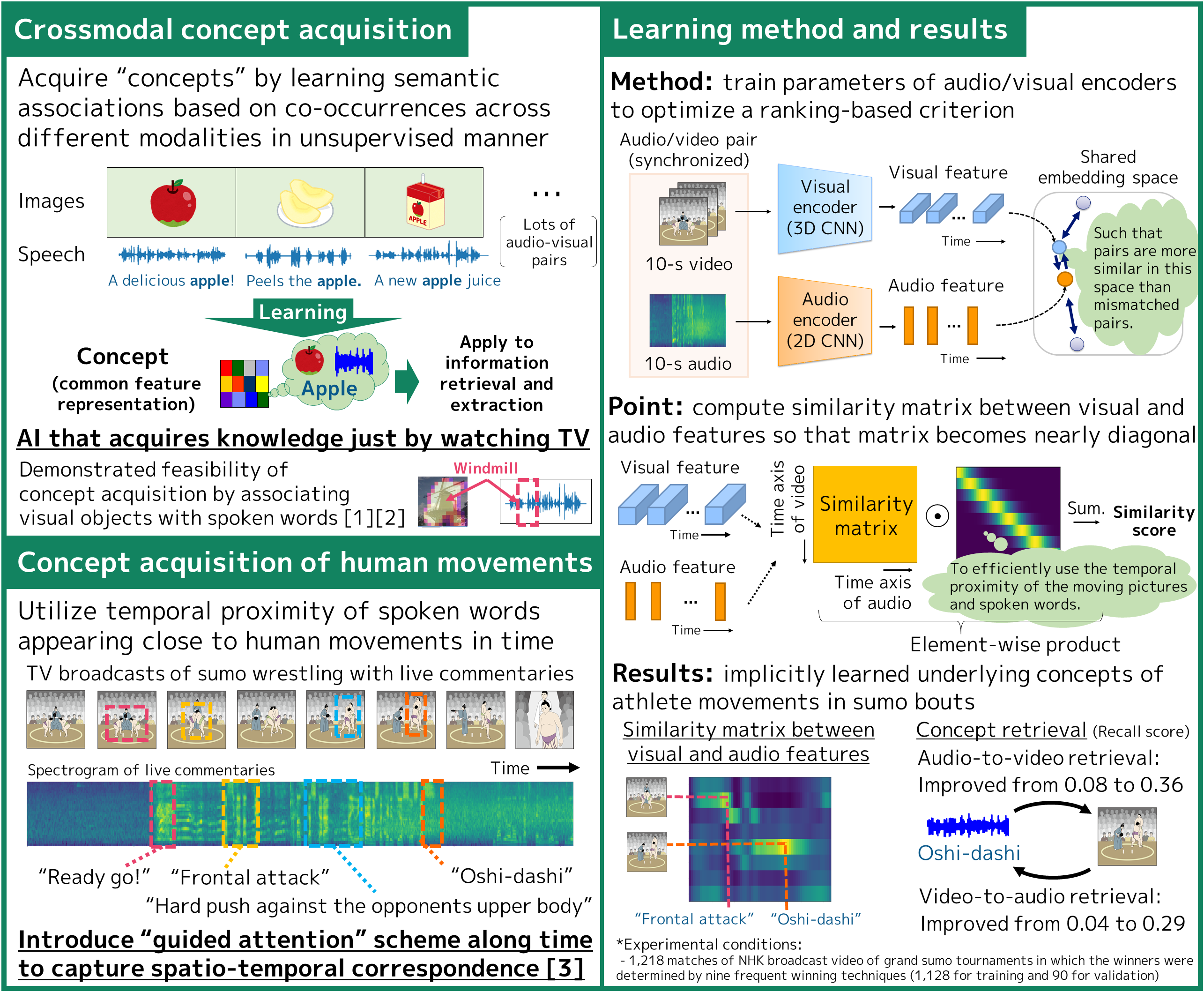
AI that acquires knowledge just by watching TVCrossmodal learning for concept acquisition of human movements 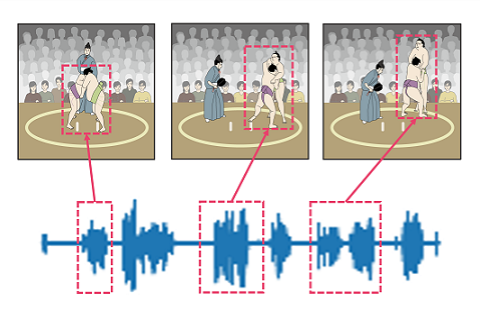
|
|---|
We developed a crossmodal learning method that can acquire "concepts" corresponding to specific objects and events on unlabeled audio and video signals. Achieving it in an unsupervised way is particularly important, since it is generally difficult to manually label all the objects and events appearing in audio-visual data for supervised learning. Our main idea was identifying concepts by looking at them from different modalities, just like looking at objects from different angles. To efficiently detect and utilize temporal co-occurrences of audio and video information, we employed a guided attention scheme. Experiments using real TV broadcasts of sumo wrestling with live commentaries show that our method can automatically associate specific athlete techniques and its spoken descriptions without any manual annotations. We are aiming for a future in which AI can acquire knowledge autonomously by just watching and listening to everyday scenes, or watching TV.
[1] Y. Ohishi, A. Kimura, T. Kawanishi, K. Kashino, D. Harwath, J. Glass, “Trilingual Semantic Embeddings of Visually Grounded Speech with Self-attention Mechanisms,” in Proc. International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2020.
[2] Y. Ohishi, A. Kimura, T. Kawanishi, K. Kashino, D. Harwath, J. Glass, “Pair Expansion for Learning Multilingual Semantic Embeddings using Disjoint Visually-grounded Speech Audio Datasets,” in Proc. Interspeech 2020.
[3] Y. Ohishi, Y. Tanaka, K. Kashino, “Unsupervised Co-Segmentation for Athlete Movements and Live Commentaries Using Crossmodal Temporal Proximity,” in Proc. International Conference on Pattern Recognition (ICPR) 2020.

Yasunori Ohishi / Recognition Research Group, Media Information Laboratory
Email: cs-openhouse-ml@hco.ntt.co.jp