

| 08 |
騒がしい環境で録音音声をクリーンな音声に変換多ストリーム拡散モデルのアンサンブル推論による音声強調 
|
|---|
| どんな研究 |
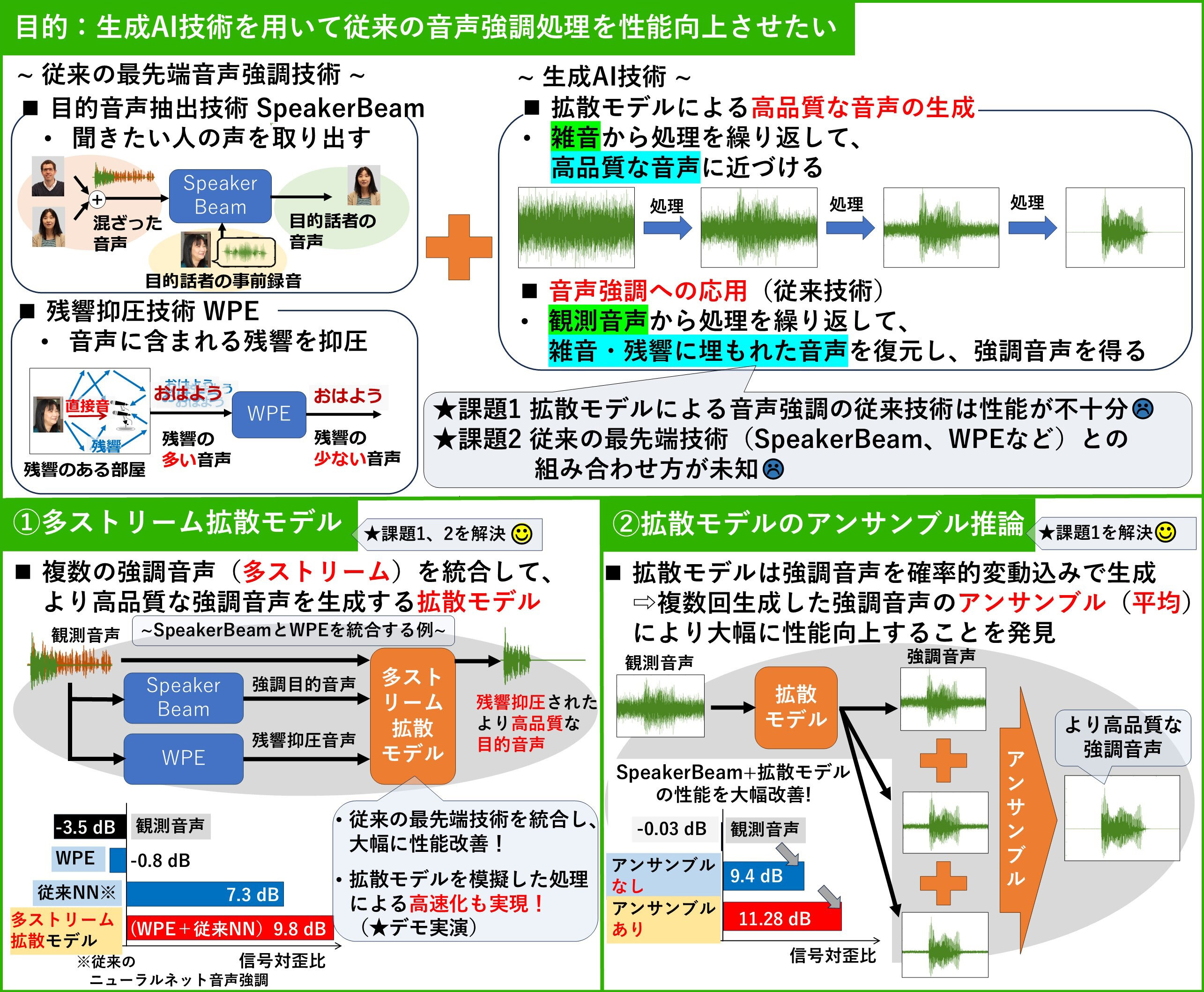
近年、生成AI技術により高品質な音声生成が可能になってきています。本研究では、生成AIを活用して録音音声から雑音や残響を高精度に除去する音声強調手法を紹介します。従来のNTT最先端音声強調技術と生成AI技術を統合し、格段に高品質な音声強調を実現します。 |
|---|---|
| どこが凄い |
生成AI(拡散モデル)による音声生成に、従来の最先端技術に基づく複数の強調音声を統合的に組み込む方法を考案し、格段に性能を向上しました。また、拡散モデルの複数回の出力を平均することが、音声強調の性能改善に極めて効果的であることを世界で初めて示しました。 |
| めざす未来 |
騒がしい環境で、目的の音声だけをスタジオで収録したような高品質な音声収録が可能になります。日常環境の中で、高品質な音声コンテンツやデータが収集できたり、より快適な遠隔会議が実現できるなど、様々な音声アプリケーションの利便性が大幅に向上することが期待できます。 |
[1] N. Kamo, M. Delcroix, T. Nakatani, “Target speech extraction with conditional diffusion model,” in Proc. INTERSPEECH, pp. 176-180, 2023.
[2] T. Nakatani, N. Kamo, M. Delcroix, S. Araki, “Multi-stream diffusion model for probabilistic integration of model-based and data-driven speech enhancement,” in Proc. IWAENC, pp. 65-69, 2024.
加茂 直之(Naoyuki Kamo)メディア情報研究部 信号処理研究グループ