

メディアの科学
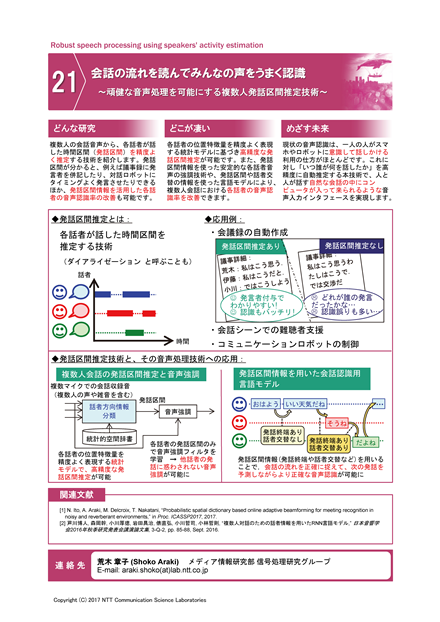
会話の流れを読んでみんなの声をうまく認識
~頑健な音声処理を可能にする複数人発話区間推定技術~
概要
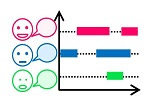
現状の音声認識は、一人の人がスマホやロボットにかなり意識して話しかける利用の仕方がほとんどです。これに対し「いつ誰が何を話したか」を高精度に自動推定できれば、複数の人と人とが話す自然な会話の中に入って来られるようなスマホやロボットができるでしょう。
本展示では、複数人の会話音声から「いつ誰が話したか」を精度よく推定する発話区間推定技術を紹介します。また「何を話したか」の推定、すなわち音声認識の認識率向上のための技術として、各話者の発話区間音声から適切に雑音を除去する技術や、発話区間や話者交替の情報を使った言語モデルなどについても合わせて紹介します。
本展示では、複数人の会話音声から「いつ誰が話したか」を精度よく推定する発話区間推定技術を紹介します。また「何を話したか」の推定、すなわち音声認識の認識率向上のための技術として、各話者の発話区間音声から適切に雑音を除去する技術や、発話区間や話者交替の情報を使った言語モデルなどについても合わせて紹介します。
当日の様子

ポスター
ポスターの画像をクリックすると、PDFファイルが開きます。





