

| 08 |
聴きたい音だけをリアルタイムで抜き出す!深層学習に基づく任意の音の低遅延選択的聴取 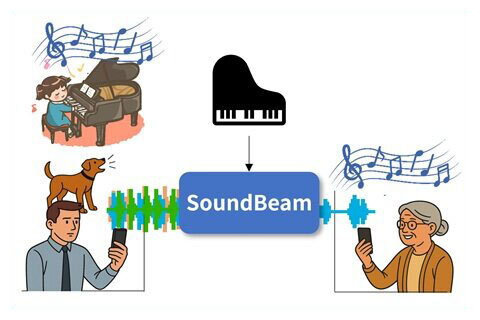
|
|---|
| どんな研究 |
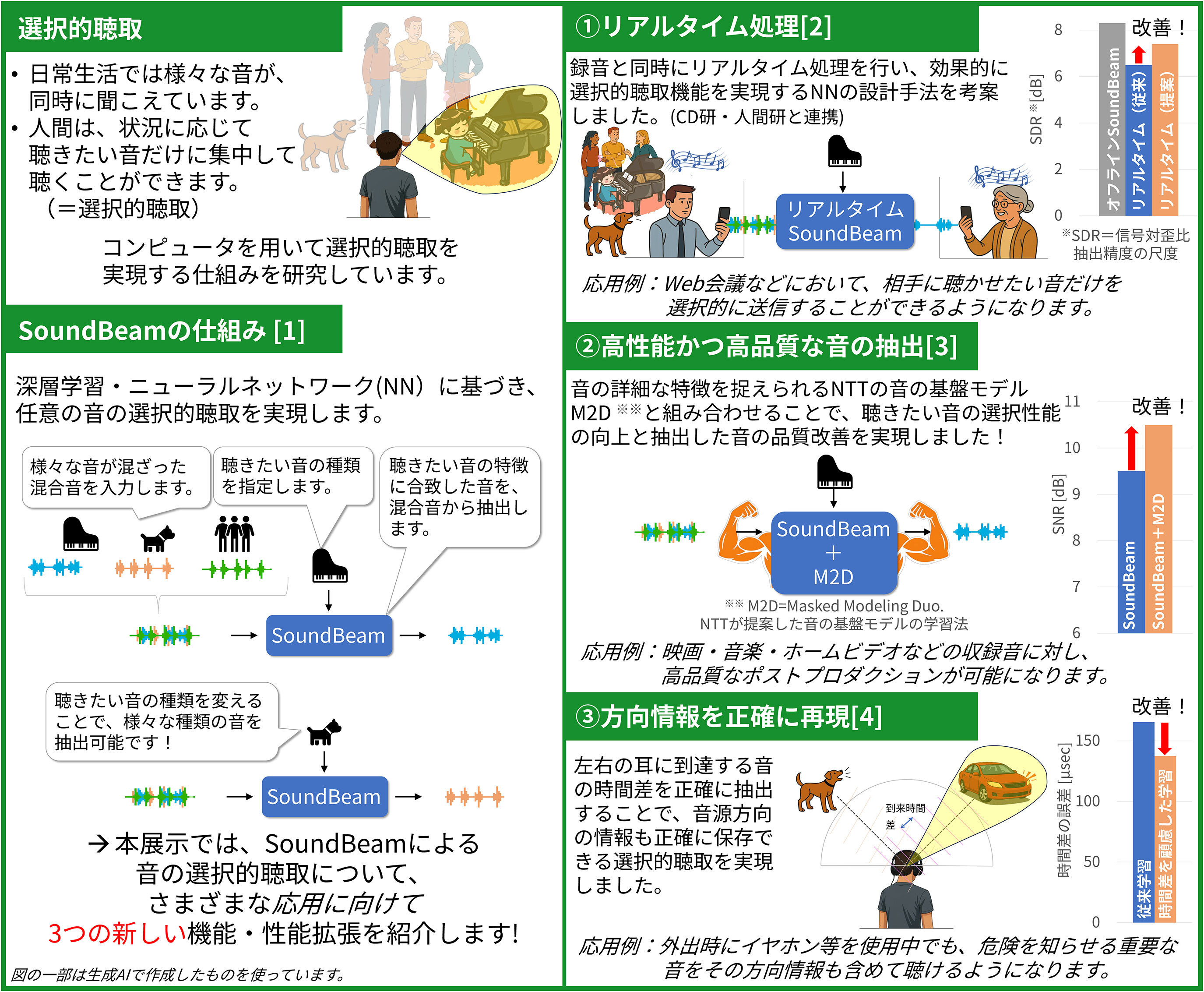
人間は、様々な音が混在する中でも、聴きたい種類の音に注目して聴くことができる、選択的聴取と呼ばれる能力を持っています。本研究では、人間が持つ選択的聴取の機能を計算機上で実現し、混ざった音から聴きたい音を取り出す技術(目的音抽出) をめざします。 |
|---|---|
| どこが凄い |
高い目的音抽出精度を保ったまま、一般的なPCでもリアルタイムで動作する目的音抽出手法を考案しました。また、音の汎用表現モデルを用いた高精度化・高品質化や、音の到来方向を検知可能なバイノーラル処理も実現し、人間の選択的聴取能力に近づけることができました。 |
| めざす未来 |
子どものピアノの音や生活の音は、在宅勤務のWeb会議では不要な音ですが、実家の祖父母との通話では大事な音かも知れません。本技術によって、周囲で鳴っている音の中から、状況に応じて聴きたい音・聴きたくない音の制御を可能とし、より快適なコミュニケーションを実現します。 |
[1] M. Delcroix, J. B. Vázquez, T. Ochiai, K. Kinoshita, Y. Ohishi, S. Araki, “SoundBeam: Target sound extraction conditioned on sound-class labels and enrollment clues for increased performance and continuous learning,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, Vol. 31, pp.121-136, 2022..
[2] K. Wakayama, T. Ochiai, M. Delcroix, M. Yasuda, S. Saito, S. Araki, A. Nakayama, “Online target sound extraction with knowledge distillation from partially non-causal teacher,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 561-565, 2024.
[3] C. Hernandez-Olivan, M. Delcroix, T. Ochiai, D. Niizumi, N. Tawara, T. Nakatani, S. Araki, “SoundBeam meets M2D: Target sound extraction with audio foundation model,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025.
[4] C. Hernandez-Olivan, M. Delcroix, T. Ochiai, N. Tawara, T. Nakatani, S. Araki, “Interaural time difference loss for binaural target sound extraction,” in Proc. 18th International Workshop on Acoustic Signal Enhancement (IWAENC), pp. 210-214), 2024. IEEE.

デルクロア マーク(Marc Delcroix)メディア情報研究部 信号処理研究グループ
本研究のうち、M2DとSoundBeamの組み合わせおよび方向情報を保存できる選択的聴取に関する部分はJST SICORP (JPMJSC2306) の支援を受けて実施しました。