

研究展示
| 09 |
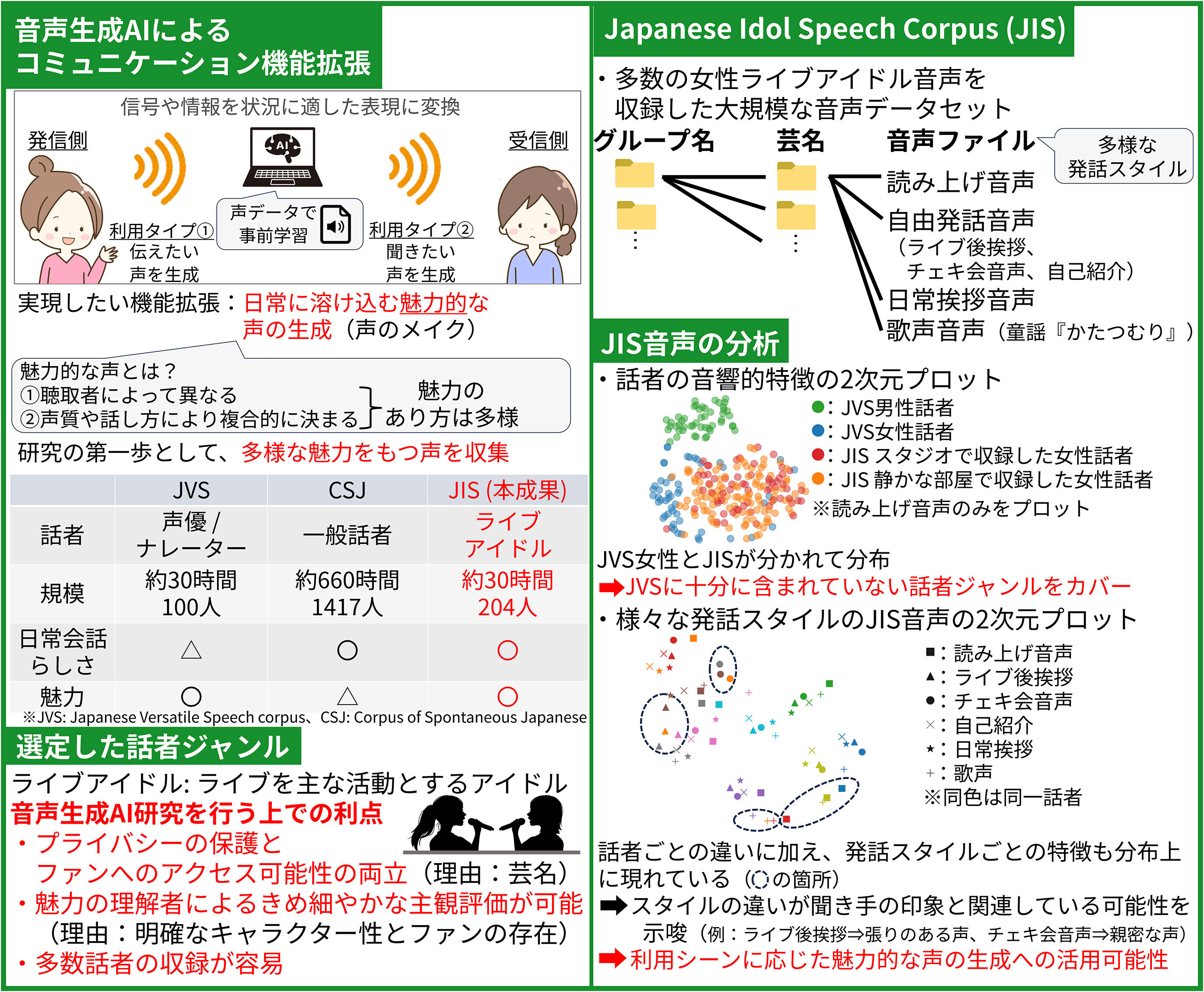
多様な魅力をもつ声を提供します音声生成AI研究用アイドル音声データセット 
|
|---|
| どんな研究 |
音声生成AIの研究開発用データは、声優など声による表現を職業の中核とする話者による演技的な発話に偏りがちです。各AIユーザにとって魅力的な音声の生成の実現をめざす第一歩として、多様な魅力を有するライブアイドルを話者とする多数話者音声データセットを構築しました。 |
|---|---|
| どこが凄い |
本データセットは、研究利用のために契約処理が適切になされた初の大規模アイドル音声データセットです(話者数200人以上、総時間約30時間)。他の音声データセットのような読み上げ音声や日常会話のみならず、チェキ会での発話などアイドル特有の魅力的な発話も含んでいます。 |
| めざす未来 |
多様な人の音声を学習することで、誰もが自分の声を柔軟に魅力的に整えられる音声生成AI、いわば「声のメイク」の実現をめざしています。この試みにより、声へのコンプレックスや発話へのためらいを軽減し、積極的な自己表現や活発なコミュニケーションを促すことをめざします。 |
[1] Y. Kondo, H. Kameoka, K. Tanaka, T. Kaneko, “JIS: A Speech Corpus of Japanese Idol Speakers with Various Speaking Styles,” in Proc. INTERSPEECH, pp. 4783-4787, 2025.

近藤 祐斗(Yuto Kondo)メディア情報研究部 事象モデリング研究グループ
本研究のうち、音声収録作業(話者募集、収録、データセット編集)に関する部分はJST CREST (JPMJCR19A3) の支援を受けて実施しました。