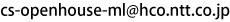聞きたい人の声に耳を傾けるコンピュータ(Ⅱ)
音声と映像を手がかりとしたマルチモーダル選択的聴取
どんな研究
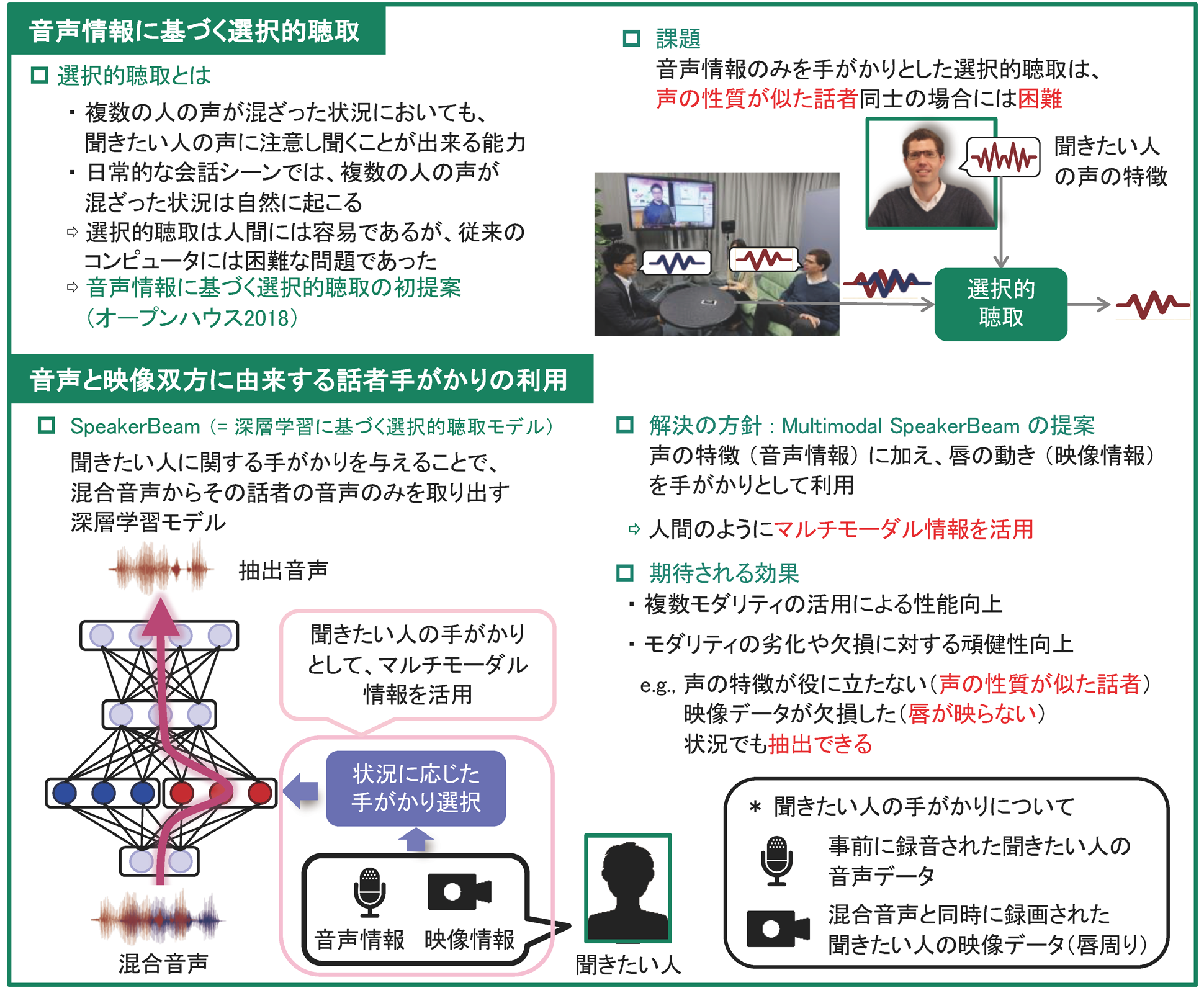
人間は、複数の人が同時に話している状況においても、聞きたい人の声に集中し、聞きたい人の声を聞き取る能力(= 選択的聴取)を持っています。本研究は、そうした人間が持つ選択的聴取の機能をコンピュータ上で実現することをめざしたものです。
どこが凄い
音声情報に加え、映像情報を手がかりとして利用する、マルチモーダル選択的聴取の技術を実現しました。人間のように複数の情報源を適切に活用することで、声の性質が似た話者の会話といった、音声情報だけでは困難であった状況でも安定して動作可能な技術へと発展しました。
めざす未来
複数の人の声が混ざった音声から「聞きたい人の声のみを抽出する技術」は、人の音声を入力とする様々なデバイスの基盤となる技術です。人を認識して対応を変えるロボットやスマートスピーカーの実現といった、人とより自然に対話するコンピュータの実現に寄与します。