少量の追加データで作るカスタム機械翻訳
汎用対訳コーパスJParaCrawlを用いた機械翻訳の領域適応
どんな研究
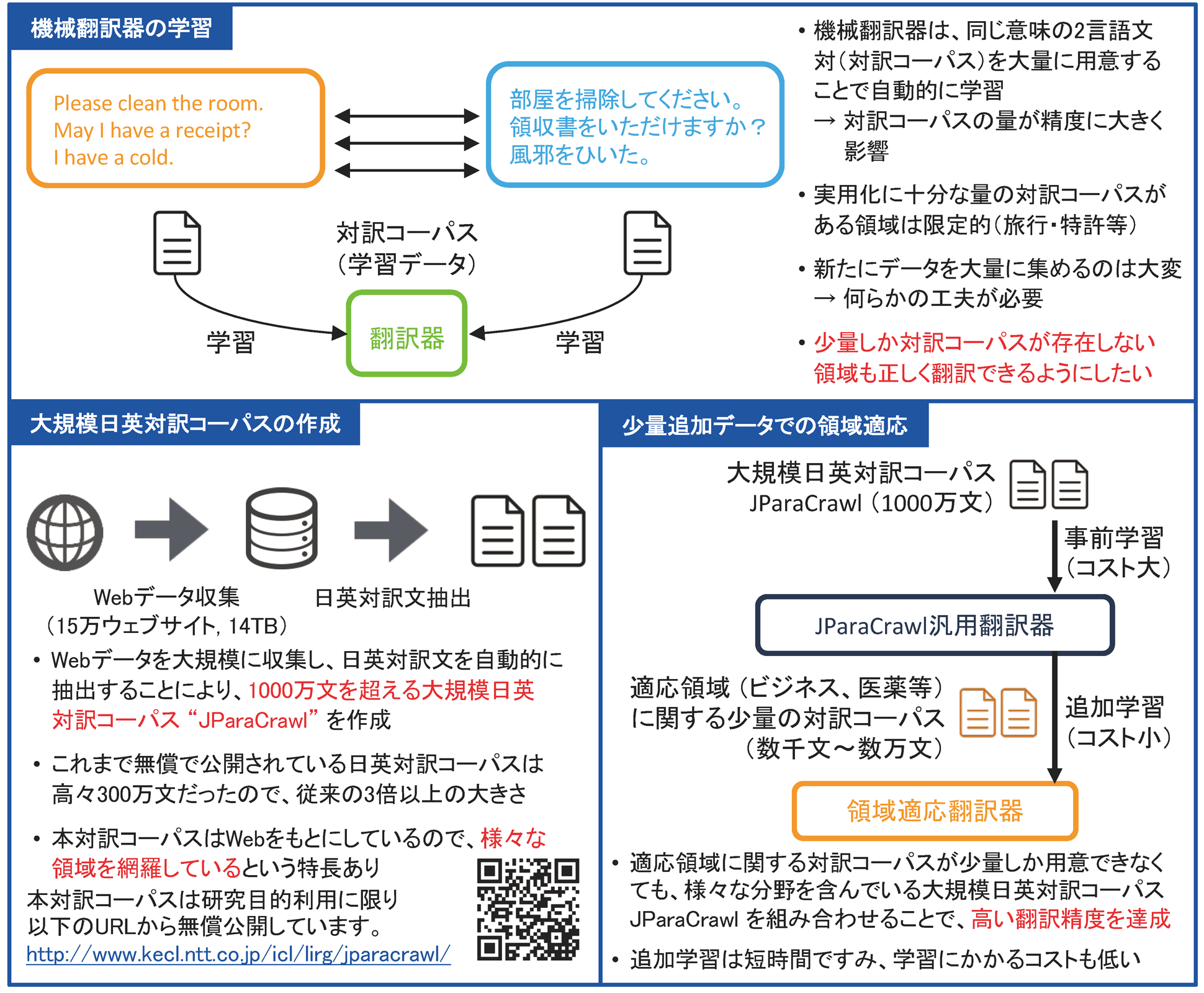
機械翻訳では、対訳コーパスと呼ばれる学習データから自動で翻訳器を学習します。そのため、特定の領域(分野)に特化した翻訳器を作成するためには、その領域の学習データが大量に必要となっていました。この展示では、少量の追加データだけで翻訳器を特定領域に特化させる技術を紹介します。
どこが凄い
Webデータを大量に収集し、自動的に対訳になっている文を見つけることで大規模な日本語-英語の学習データを作成しました。この学習データは様々な領域を網羅しているため、これを併用することで少量の学習データだけで特定領域への翻訳器を特化させることが可能になりました。
めざす未来
本技術を用いることで、これまで学習データが乏しかったため翻訳精度が低かった領域に対しても、少量の追加学習データで翻訳精度を飛躍的に向上させることが可能になります。将来的には、どの領域に対しても高精度な機械翻訳の実現をめざします。