

研究展示
| 01 |
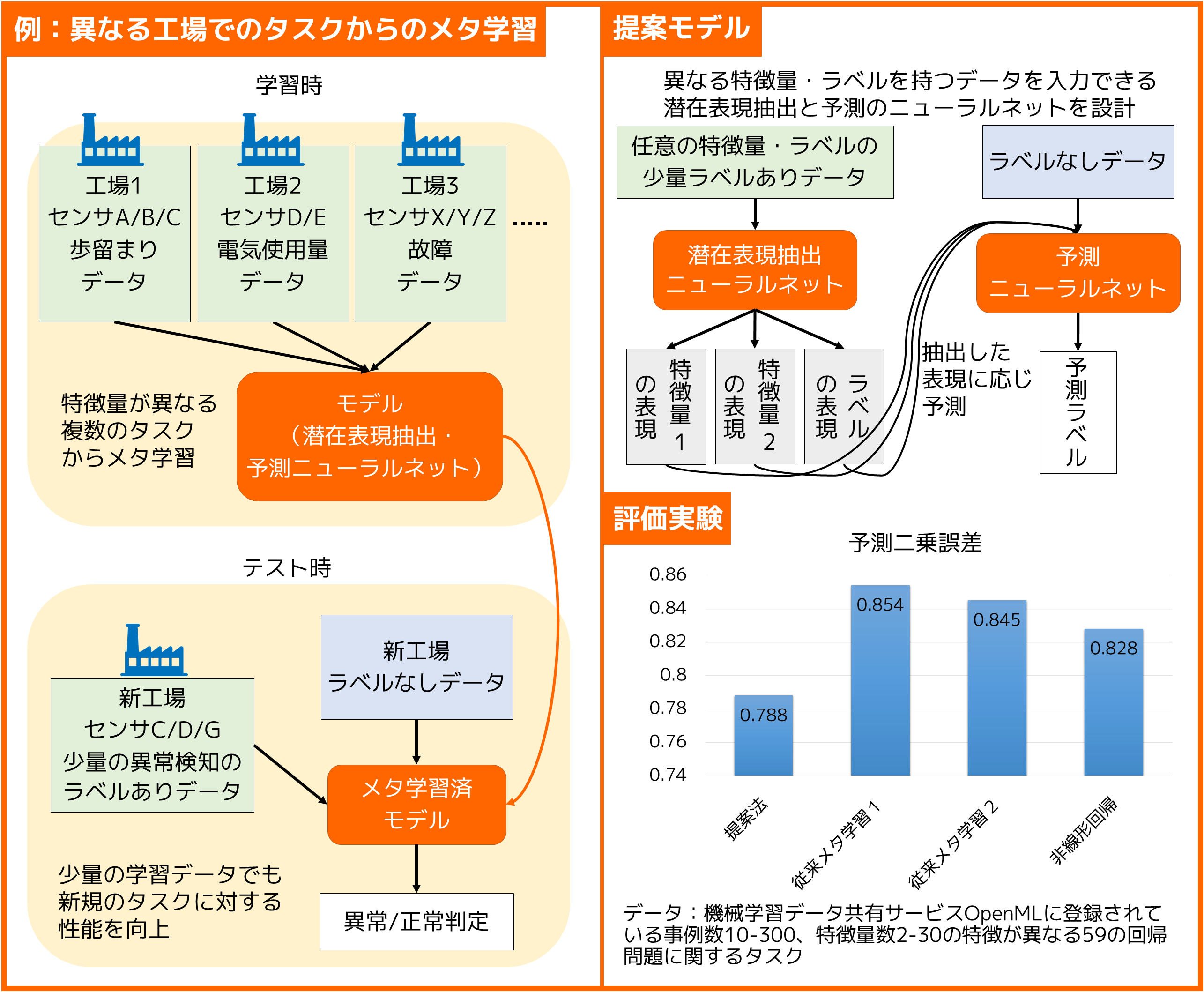
いろんなデータから学習法自体を学習します特徴量が異なるタスク群からのメタ学習 
|
|---|
| どんな研究 |
深層学習で高性能を達成するためには膨大な学習データが必要です。本研究では、複数の異なるタスクのデータを活用することで、目的のタスクにおいては少量のデータでも高性能を達成する手法を考案しました。これにより例えば異なる工場でのデータからの学習が可能となります。 |
|---|---|
| どこが凄い |
ニューラルネットを用いた従来のメタ学習では、特徴量やラベルが異なるタスクのデータを同時に扱えませんでした。本研究では、特徴量やラベルが異なるタスクのデータを扱うことができるニューラルネットを設計し、それを活用したより柔軟なメタ学習を実現しました。 |
| めざす未来 |
機械学習の適用を考える際、少量の学習データしか入手できない適用分野の場合は、機械学習技術を有効に活用することができません。本技術を発展させることで、機械学習技術の適用範囲を広げ、様々な分野で価値を生み出していくことをめざします。 |
[1] T. Iwata, A. Kumagai, “Meta-learning from Tasks with Heterogeneous Attribute Spaces,” in Proc. Neural Information Processing Systems (NeurIPS), 2020.
動画の公開は終了いたしました。ご了承くださいますようお願いいたします。
Q&A の公開は終了いたしました。ご了承くださいますようお願いいたします。

岩田 具治 (Tomoharu Iwata) 上田特別研究室
Email: cs-openhouse-ml@hco.ntt.co.jp