| Q.質問/コメント | A.回答 |
| Q.質問/コメント モデルの種類(GPT-2やBlender )と事前学習モデルのパープレキシティを教えてください。
もし複数のモデルサイズを試していらっしゃればサイズごとのパープレキシティの変化も教えてください。 | A.回答 今回はBlender(Encoder-decoder)のみ検証しております.
事前学習モデルのTwitterデータ上でのパープレキシティは,1.6Bモデルで30程度,0.35Bモデルで36程度です.
Finetuneモデルのパープレキシティについては,対象コーパスによって異なりますが,趣味雑談コーパス上でおおよそ18程度でした.
0.35Bのモデルとの差は2-3ポイント程度です. |
| Q.質問/コメント とても面白い研究発表をありがとうございます。
数年前seq2seqなどで「わかりません」「うん」ばかりを返す対話ボットを触っていた者としては、とてもワクワクしました。
?
?一点個人的な興味からですが、お尋ねします。?
実際杉山さんが、大規模なデータを用いて研究を行ってみた感触が知りたいです。
対話システムの精度向上には、大規模な学習データが要であり(特に事前学習用の)、必要不可欠であるものと感じましたでしょうか。??それとも、小規模なデータでも、同程度のシステムが構築が可能であるとお考えでしょうか。?
また、先端を走るNTTさんに、Pre-trainedモデルを公開して公共の知として頂けたなら、対話の研究を志すものにとっては大変嬉しく思います。?
再度、面白い研究発表をありがとうございました。 | A.回答 ご質問ありがとうございます。
今回のシステムのようにオープンドメインで何度も対話する場合は、大規模データは必要不可欠な要素だと考えています。少なくとも今の深層学習ベースのシステムは、表層的には賢く判断しているように見えるものの、結局のところは見たことのある情報の共起関係に基づいて動作するに留まっています。そのため、それなりの密度を持って対話に現れる情報の空間を埋めきることが、スタートラインに立つ必要条件だと思います。
ただ、スタートラインに立った後は、単にテキストデータの規模やモデルパラメータ数を増やすだけでは不十分なようです。何らかの形でPre-trainモデルを公開することで、こうした「次」の課題に日本全体で取り組める流れを作っていきたいと考えています。
なお参考までに、ドメインをうまく誘導して一回のみの対話をそれっぽく見せるだけでしたら、タスク指向の対話に近いやり方で、比較的少数のルール+DBからの情報で実現可能です。ライブコンペ1・2では、そういう作りのシステムで1位,2位を取っていました(ニューラルで少数データでやるのは無謀ですが)。 |
| Q.質問/コメント 研究講演を拝見させていただきました。大変勉強になる講演ありがとうございました。講演内で、大規模深層学習に基づく雑談対話システムのデモ動画が公開されていましたが、そちらについて質問です。
デモ動画ではロボットが旅行に行けないという話題に関して対話しておりましたが、文章だけの対話システムであれば問題ないように感じられますが、身体性を持つロボットとの対話である場合、身体性に見合った話題でない(旅行を経験したことがあるのか・妊娠は不可能ではないか)ように見受けられました。
また、別の研究においてキャラクタらしい発話の研究をされていましたが、 身体性を持つロボットに、その見た目や機能に合った話題や個性を持たせて対話を行うようなシステム の研究は今後予定されていますでしょうか? | A.回答 ご視聴・ご質問ありがとうございます。
おっしゃる通り、身体を持つロボットが対話する場合に身体性と話題が矛盾すると違和感が生じますので、見た目や機能に即した個性の付与・話題展開について取り組んでいく予定です。こうした個性は人間とは大きく異なるため、そうした特殊な学習データの収集、もしくは一般的なデータからの学習方法の開発が課題と考えております。
一方、この問題は非常に根が深く、どう扱うべきか非常に難しい問題だと感じています。もちろんご覧いただいた通り、身体性と矛盾すると違和感が生じます。しかしながら、逆に見た目や機能に完全に準拠させる方針ですと、対象とするロボットによっては実世界に接地した話題全般を扱えず、対話がつまらなくなるなどの弊害が生じます。この辺り、対話の用途やユーザの心構え(嘘でも別に楽しく話せればよいとか)によってバランスや最適解が変わる話ですので、要素技術の開発のみならず、実際のサービスとしてのニーズや運用も含めて検討していきたいと考えております。 |
| Q.質問/コメント 特に「対話欲求を継続的に満たし続ける、パートナーとなりうる雑談相手となるような対話システム」を考えた時,その発話の自然さは何も入力や文脈とのズレのみに依存する訳ではないと思います.
たとえば職業が会社員だと言っていた対話システムに「仕事中に楽しいことってある?」と聞いて「やっぱりホームランを打った時ですね!(野球選手のような発言)」と返答されると属性の一貫性の欠如を感じ,強い違和感を覚えます.同様の事が性格や趣味嗜好などにも言えると思います.短い対話であれば文脈として処理できそうですが,パートナーとなり得るものを目指す場合は長期間の対話を考える必要があり,文脈として保持するのはかなり難しいように感じます.
このような不自然さを発生させないような工夫などは行っているのでしょうか.また「強い違和感を感じる発話が7%ほど存在」,「矛盾・話題の飛び・事実と異なる発話が含まれる場合に主観評価が大きく低下」とありますが,ここには上述したような要素に基づく不自然な発話は含まれますか? | A.回答 おっしゃる通り、パーとなりうる対話システムの実現には、長期間繰り返す対話における(言外の推論を含む)矛盾の抑制が課題の一つと考えております。ただ、ご覧いただいたシステムではそうした高度な抑制処理は実現できておりません。現在、長期間にわたるチャットデータを収集し、その中に出現した情報を人がどのように利用しているのか、といった分析や、対話履歴自体を外部知識と捉えてそことの矛盾を抑制する研究などに取り組んでいます。
なお、「強い違和感を感じる発話が7%ほど存在」,「矛盾・話題の飛び・事実と異なる発話が含まれる場合に主観評価が大きく低下」にも、ご指摘いただいた要素を含む不自然な発話が一定数含まれています。もう少し直接的な例ですが、ありがちな例としては、システムが「有川浩さんの小説をよく読みます」と言っているのに、おすすめを聞くと答えられない、もしくは別な作家の作品を出してしまう、といったものです。 |
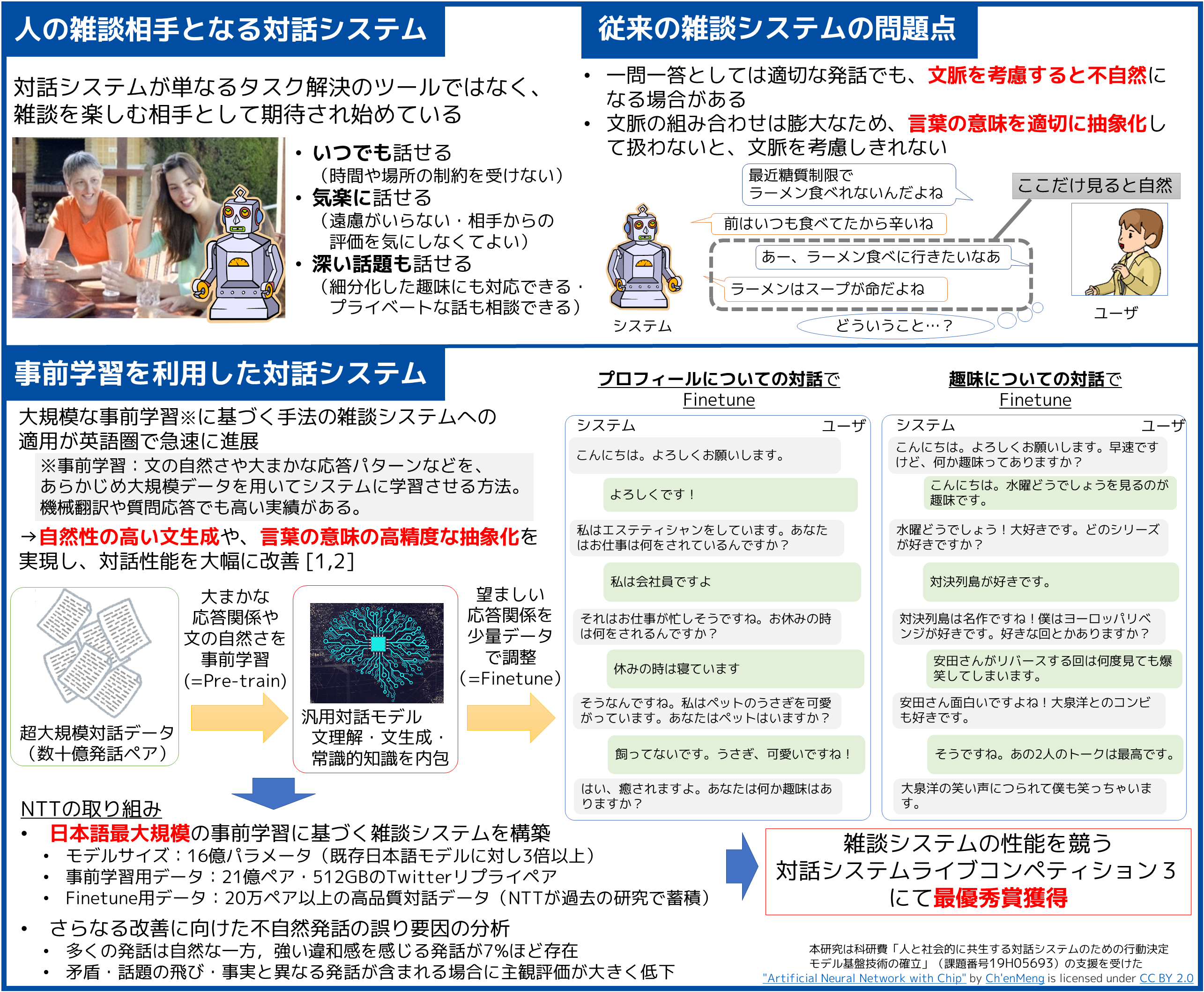
| Q.質問/コメント 一問一答としては自然だが文脈を考慮すると不自然になる返答の解消が目的の一つであったと思うのですが、会話ペアを学習に用いるというのはこの目的から外れているよう思われます。7%の不自然発話はこの会話ペア学習の弊害であるとは考えられませんか? この点について検討したことがあれば教えてください。 | A.回答 ご質問ありがとうございます。
説明を省略してしまいましたが、数発話(メモリ制約上最大4発話)の文脈をまとめて入力文とし、それと対応する出力文との対を「ペア」として学習しております。そのため、文脈として入力された範囲に限り、文脈を反映した応答が可能になっています。
ただ、4発話を超えた部分については全くケアできていなため、少し離れた箇所の発話との矛盾が多く発生しています。このあたりの問題については、入力可能な文脈長を伸ばしたり、別途矛盾判定器でフィルタするなどの対応を検討中です。 |
| Q.質問/コメント Fine-tunedモデルの公開は難しいかもしれませんが、Pre-trainedモデルだけでも公開していただけると日本の対話研究が進むと思いますので、ぜひご検討ください。 | A.回答 Pre-trainモデルの非商用利用での公開を、現在前向きに検討中です。公開されましたらぜひご利用いただけますと幸いです。 |
| Q.質問/コメント デモが動作するWebサイトなどを公開する予定はありますか。 | A.回答 申し訳ありませんが、コンピューティングリソースの確保の困難さや不適切発話が生成されうるリスクを考慮し、現時点ではデモサイトとして完全にフリーで公開する予定はありません。
逆にこれらの問題の解消に目処がついた場合や、利用登録を明示的にいただくなどの形式であれば公開可能となるかもしれませんので、方法を検討したいと思います。 |
| Q.質問/コメント 事前学習用のデータやFinetune用データの数を「ペア」と表現されていますが、これはいわゆる一問一答形式のデータでしょうか。もしそうであるならば、なぜそれらのデータで一問一答でない”文脈”を学習することができるのでしょうか? | A.回答 ご質問ありがとうございます。
説明を省略してしまいましたが、数発話(メモリ制約上最大4発話)の文脈をまとめて入力文とし、それと対応する出力文との対を「ペア」として学習しております。そのため、文脈として入力された範囲に限り、文脈を反映した応答が可能になっています。 |
| Q.質問/コメント いつ頃このレベルのシステムと私のスマホでしゃべれるようになるのでしょうか? | A.回答 数年以内と考えています.現在は実行時の計算量が大きく,サービス料金を高く設定しないとマネタイズが難しいですが,数年程度で十分手元で動かせる程度にハードウェアが進歩するのではと考えています. |
| Q.質問/コメント 今回のシステムを作るにあたって,どのくらいのリソースがかかったのでしょうか. | A.回答 計算リソースについては、GPU(V100)400枚を2日間程度占有し学習しております。
学習データについては、Twitterから抽出した21億発話ペアをPre-trainに使用し、これまでのNTTの研究で蓄積してきた高品質対話データ20万発話ペアをFine-tuneに使用しています。 |