

| 16 |
TVを視聴するだけで賢くなるAIクロスモーダル学習による動作概念の獲得 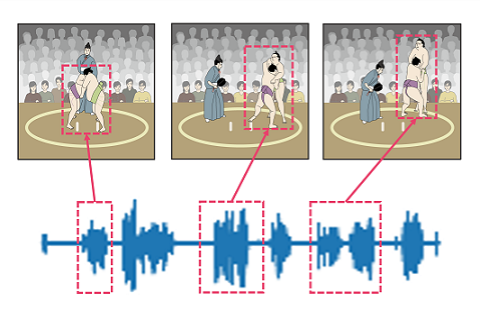
|
|---|
| どんな研究 |
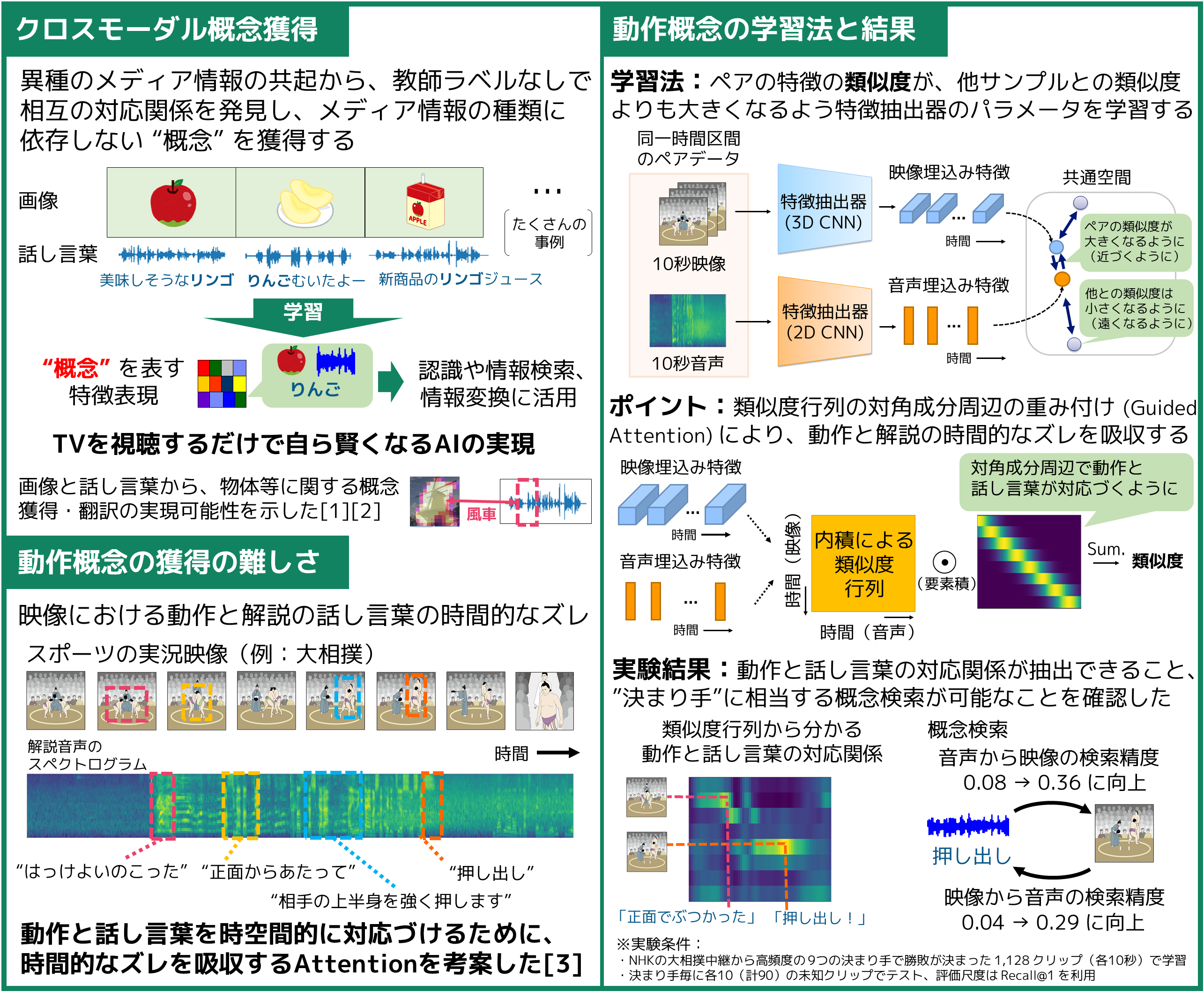
大量データの準備には、手間がかかったり、データの入手自体が難しかったり、クラスラベルの付け方を事前に設計することが難しかったりします。この展示では、TV放送のようなメディアデータだけから、モノやコトの概念を自動獲得するAIを、より高度な認識や検索に活用する研究を紹介します。 |
|---|---|
| どこが凄い |
教師ラベルなしで映像における動作とそれを説明する話し言葉を時空間で対応付け、概念に相当する特徴表現を獲得する技術を考案しました。スポーツ実況の映像と音声データから、競技者の動作と実況の話し言葉の対応付けによる概念検索を実現しました。 |
| めざす未来 |
TVを視聴するだけで、AIが音と映像を対応付けながら、知らないモノやコトを自ら学び、賢くなる未来をめざしています。音や映像、言語といったメディアの種類を横断する超大規模アーカイブ検索や自動アノテーションなどへの応用を検討しています。 |
[1] Y. Ohishi, A. Kimura, T. Kawanishi, K. Kashino, D. Harwath, J. Glass, “Trilingual Semantic Embeddings of Visually Grounded Speech with Self-attention Mechanisms,” in Proc. International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2020.
[2] Y. Ohishi, A. Kimura, T. Kawanishi, K. Kashino, D. Harwath, J. Glass, “Pair Expansion for Learning Multilingual Semantic Embeddings using Disjoint Visually-grounded Speech Audio Datasets,” in Proc. Interspeech 2020.
[3] Y. Ohishi, Y. Tanaka, K. Kashino, “Unsupervised Co-Segmentation for Athlete Movements and Live Commentaries Using Crossmodal Temporal Proximity,” in Proc. International Conference on Pattern Recognition (ICPR) 2020.

大石 康智 (Yasunori Ohishi) メディア情報研究部 メディア認識研究グループ
Email: cs-openhouse-ml@hco.ntt.co.jp