

研究展示
| 10 |
文章の隠れた構造を見える化します疑似正解データを活用したニューラル修辞構造解析 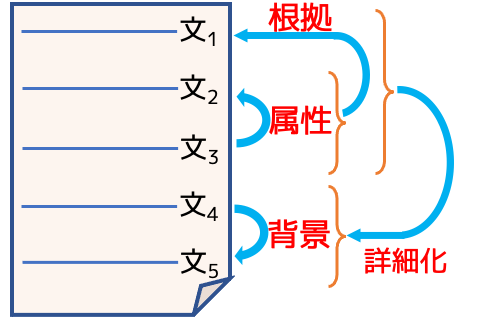
|
|---|
| どんな研究 |
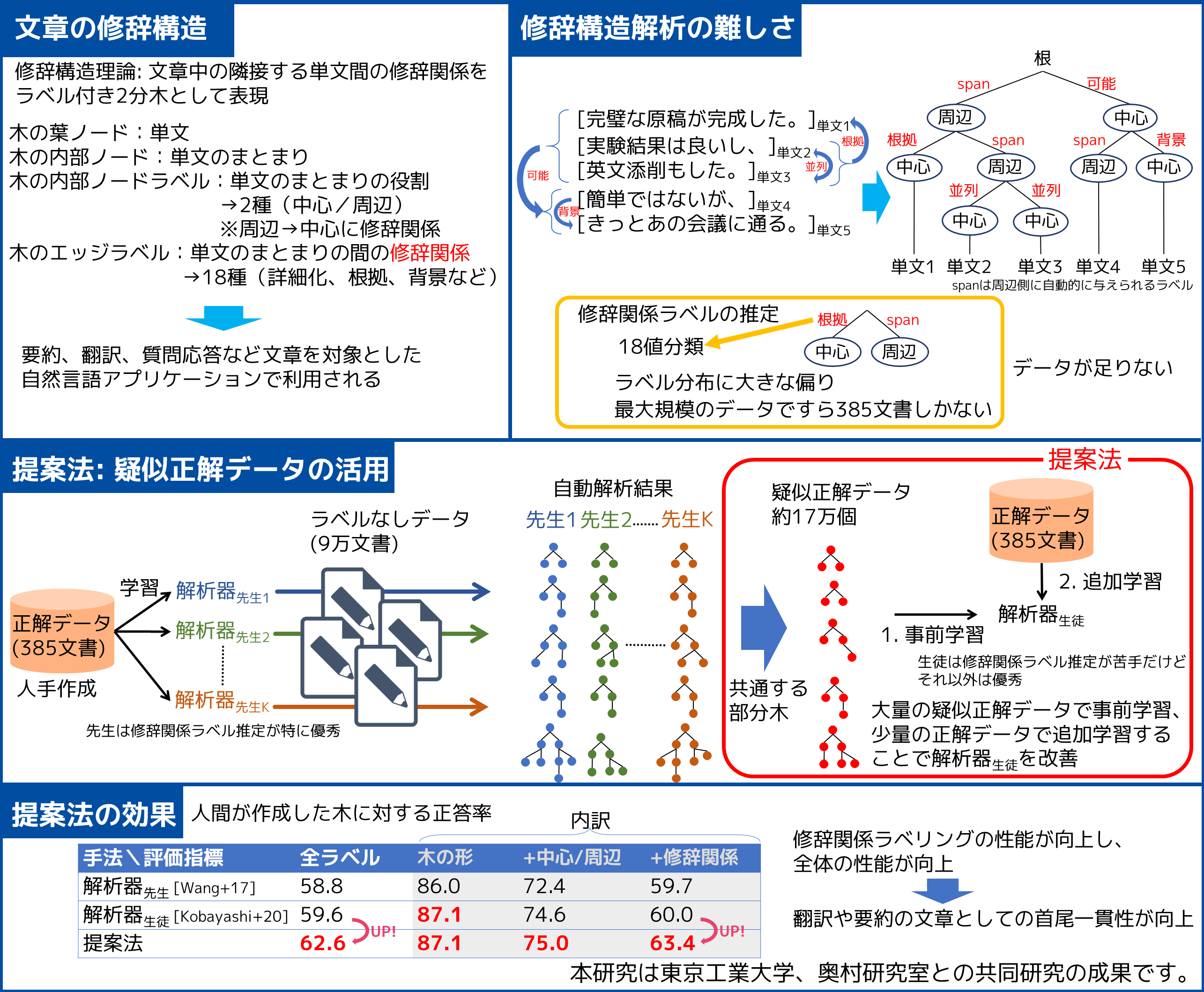
文書において、文書内のそれぞれの文どうしは意味を構成するために関わりがあります。こうした文と文の間の意味関係を明らかにする修辞構造理論は、文書をラベル付き木としてあらわします。本展示ではそれを自動で解析する修辞構造解析技術についてご説明します。 |
|---|---|
| どこが凄い |
修辞構造解析技術は教師あり学習を用いているため、性能の向上には人手で作成した正解データが大量に必要でした。提案法では既存の自動解析結果を組み合わせて疑似的な学習データを作ります。これにより、人手コストをかけることなく解析性能を向上できます。 |
| めざす未来 |
文脈を解釈することでより自然な要約や 翻訳を実現することができます。修辞構造解析技術はこうした文脈を解釈する処理の基盤となります。本技術をさらに発展させ実用に耐えうる解析器を実現することで、要約や翻訳の性能向上をめざします。 |
[1] N. Koabayashi, T. Hirao, H. Kamigaito, M. Okumura, M. Nagata, “Improving Neural RST Parsing Model with Silver Agreement Subtrees,” in Proc. 2021 Annual Conference of the Noth American Chapter of the Association for Computational Linguistics, 2021.
動画の公開は終了いたしました。ご了承くださいますようお願いいたします。
Q&A の公開は終了いたしました。ご了承くださいますようお願いいたします。

平尾 努 (Tsutomu Hirao) 協創情報研究部 言語知能研究グループ
Email: cs-openhouse-ml@hco.ntt.co.jp