

| 04 |
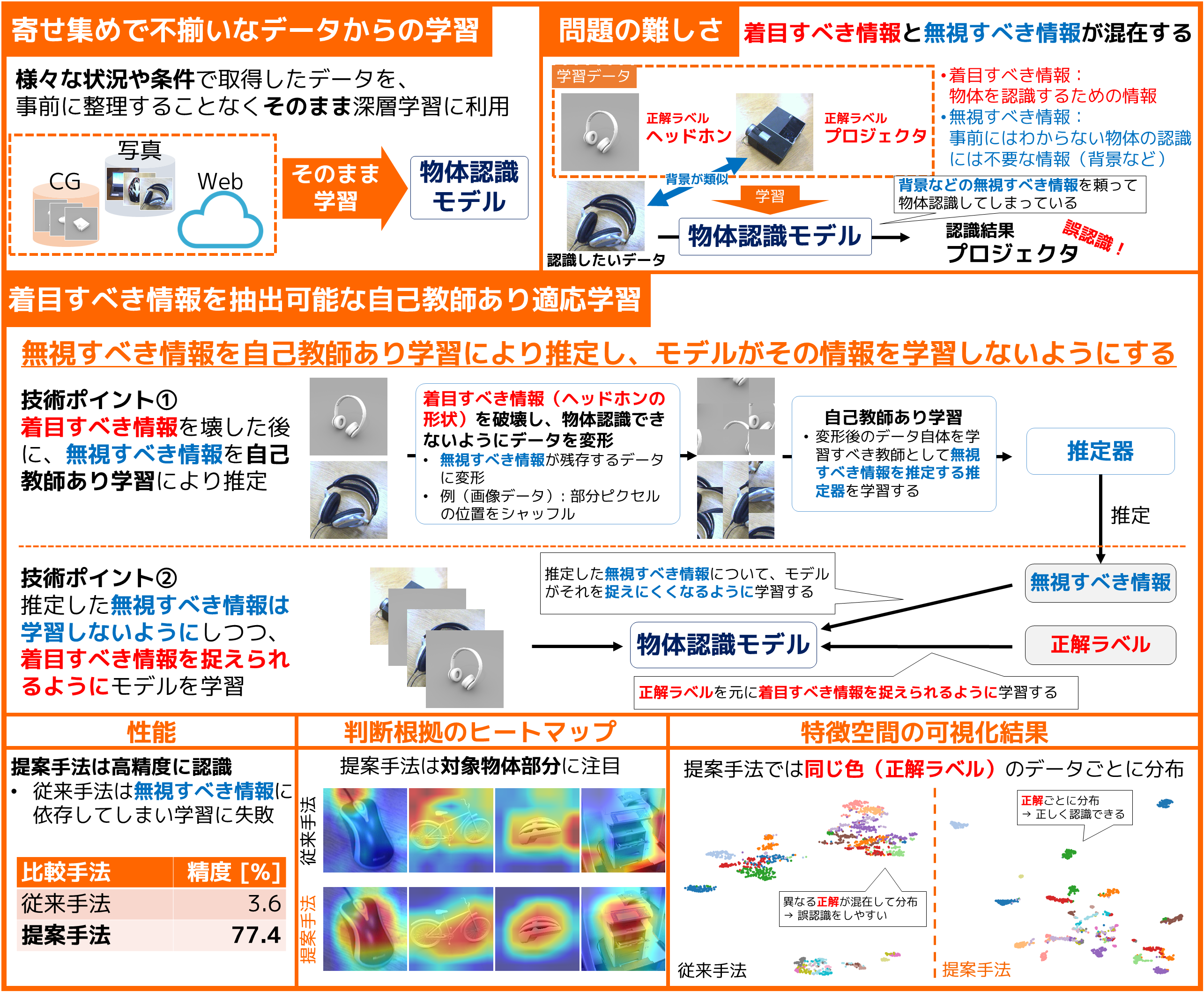
寄せ集めで不揃いなデータでも学習できます未知ドメイン・未知クラスへの自己教師あり適応学習 
|
|---|
| どんな研究 |
深層学習には、質・量ともに学習に適したデータセットが必要になりますが、それが入手可能となる場面は限られます。本研究では、様々な状況や条件で取得した寄せ集めのデータでも、事前に整理することなく、そのまま深層学習に利用できる手法を提案します。 |
|---|---|
| どこが凄い |
寄せ集めのデータで学習する場合、「着目すべき情報」だけでなく「無視すべき情報」も捉えてしまい、モデルの認識性能が低下する問題が頻発します。提案手法では、「無視すべき情報」を推定し、この影響を受けないように学習することで、モデルの認識性能を飛躍的に改善しました。 |
| めざす未来 |
様々な医療機関の診療データや、複数の工場設備のメンテナンスデータなど、現実には不揃いで寄せ集めのデータが多く存在します。本研究によって、これらのデータが活用が容易になり、従来の深層学習の枠組みを越えたデータ活用による、新たなサービスの創出に貢献します。 |
[1] 三鼓悠, 入江豪, 伊神大貴, 柴田剛志, “教師なしドメイン適応の一般化とその解法,” 第23回 画像の認識・理解シンポジウム(MIRU), 2020.
[2] Y. Mitsuzumi, G. Irie, D. Ikami, T. Shibata, “Generalized Domain Adaptation,” in Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
[3] R. Tobias, R. Stiefelhagen, “Adaptiope: A Modern Benchmark for Unsupervised Domain Adaptation,” in Proc. IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021.

三鼓 悠 (Yu Mitsuzumi) メディア情報研究部 メディア認識研究グループ
Email: cs-openhouse-ml@hco.ntt.co.jp